
[논문리뷰] Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 정리
Posted: Updated:
‘Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks’ 논문을 한글로 번역한 내용은 여기에서 확인하실 수 있습니다.
Abstract
LLM은 지식에 정확하게 접근하고 활용하는 능력이 제한적이다.
따라서 지식 집약적 작업에서 특화된 아키텍처에 비해 성능이 떨어질 수 있다.
또한, 답변에 대한 출처를 제공하거나 새로운 지식을 업데이트하는 것이 어렵다.
이러한 문제를 해결하기 위해 검색 증강 생성(Retrieval-Augmented Generation, RAG) 모델을 제안한다.
RAG는 사전 학습된 parametric(매개변수적) 메모리와 non-parametric(비매개변수적) 메모리를 결합한 언어 생성 모델이다.
parametric 메모리는 사전 학습된 seq2seq 모델, non-parametric 메모리는 사전 학습된 신경망 검색기(neural retriever)를 통해 접근할 수 있는 위키피디아의 밀집 벡터 인덱스이다.
RAG (Retrieval-Augmented Generation)
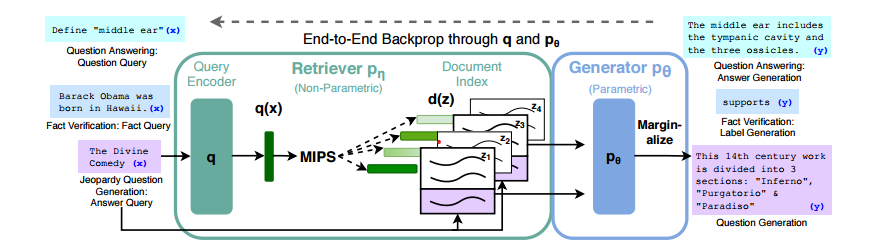
RAG 모델은 크게 두 부분으로 구성된다.
하나는 non-parametric인 retriever(검색기)이고, 다른 하나는 parametric인 generator(생성기)이다.
-
Query Encoder (질의 인코더): 사용자의 질의(query)를 입력으로 받아 벡터 형태로 인코딩한다. 이 질의 벡터는 문서 검색을 위한 키로 사용된다.
-
Document Index (문서 인덱스): 저장된 문서 데이터베이스로부터 질의에 관련된 문서들의 벡터를 담고 있다. 이 인덱스는 pre-trained neural retriever에 의해 생성되며, 각 문서는 벡터 형태로 표현된다.
-
Maximum Inner Product Search (MIPS): 인코딩된 질의 벡터와 문서 인덱스 내의 문서 벡터들 사이에서 최대 내적 값을 가지는 상위 K개 문서를 찾는다. 이 과정을 통해 가장 관련성이 높은 문서들이 검색된다.
-
Generator (생성기): 검색된 문서들과 질의를 결합하여 최종 응답을 생성한다. 이 생성기는 parametric memory를 사용하는 seq2seq 모델(예: BART)을 기반으로 한다.
-
Marginalize: 다양한 검색 결과에 대한 생성기의 응답을 합산하여 최종 출력을 결정한다.
RAG 모델은 end-to-end 방식으로 fine-tuning 되며, 질의에 따라 검색된 문서를 잠재 변수로 처리한다. 이 모델은 기존의 seq2seq 작업에 fine-tuning 될 수 있으며, generator와 retriever가 함께 훈련되어 한 번에 최적화된다.
댓글남기기